The Summarizer API helps you generate summaries of information in various lengths and formats. Use it with Gemini Nano in Chrome to perform client-side inference, and concisely explain complicated or long texts.
When performed client-side, you can work with data locally, which lets you keep sensitive data safe and can offer availability at scale. However, the context window is much smaller than with server-side models, which means very large documents could be challenging to summarize. To solve this problem, you can use the summary of summaries technique.
Key Term: The context window is the amount of text a large language model (LLM) can process at one time, measured in tokens. For context, a client-side model may process thousands of tokens at once, whereas a server-side model can process 1 million tokens.
What is summary of summaries?
To use the summary of summaries technique, split the input content at key points, then summarize each part independently. You can concatenate the outputs from each part, then summarize this concatenated text into one final summary.
As generative AI has become more widely available, we’ve seen how widely the quality of results can vary. In fact, there are several components that impact result quality, such as which large language model (LLM) you’re using, model size, and prompt quality.
As a technical writer, quality prompt writing is pretty close to a summary of a key job component: ask the right questions of the right people to get the best possible information to shape what I produce. I go to the subject matter expert (SME), who may be an engineer, a product manager, a UX researcher, or another technical writer.
In my day-to-day work for Google Chrome, some of my questions could be asked of an LLM, but that requires the model have pre-existing information or to be given the context within the prompt itself.
Prompt quality is impacted by the level of details provided, initial information accuracy, description of expected format, and so much more. Prompt engineering is the practice of asking better questions to generate the best possible response for your needs.
If you’re wondering how to be a better prompt engineer (or a better tech writer!), keep reading to learn best practices.
I was very fortunate to continue spreading the documentation gospel at Web Directions Summit 2022 in Sydney, Australia.
This talk has transformed as I’ve given it over the last several years. This edition highlighted the importance of creating accessible content.
In particular, accessible documentation should have:
Inclusive language. This starts with self-reflection in the ways in which we’ve internalized ableism, racism, sexism, etc in our everyday life. We cannot do better without recognizing where we fail.
Semantic HTML. This means your headers are not just visually larger than body text, but also represented by the correct HTML structure.
Meaningful alt and link text. If you’re already writing documentation and you take one best practice away from today, stop using “Click Here”. Replace it with copy that reflects the actual link.
The Aggregation Service can be tested with the Attribution Reporting API and the Private Aggegration API for Protected Audience API and Shared Storage.
The explainer outlines key terms, useful for understanding the Aggregation Service.
Secure data processing
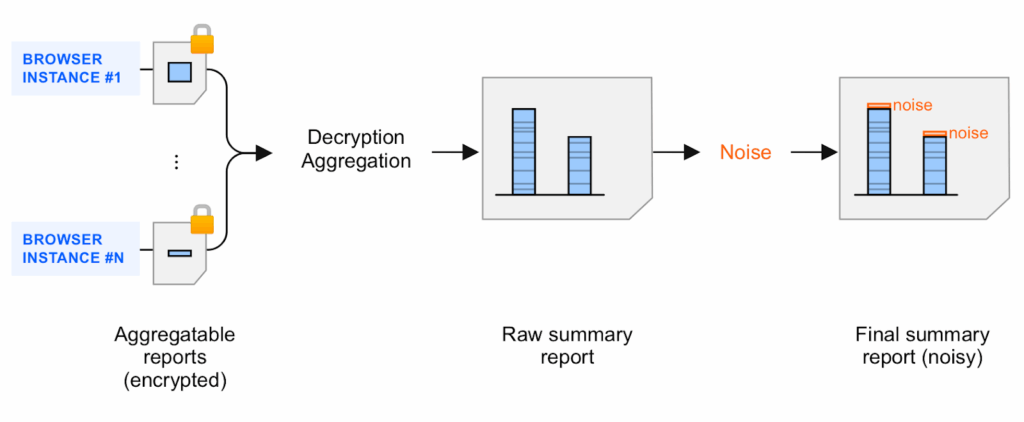
The Aggregation Service decrypts and combines the collected data from the aggregatable reports, adds noise, and returns the final summary report. This service runs in a trusted execution environment (TEE), which is deployed on a cloud service that supports necessary security measures to protect this data.
Key-Term: A Trusted Execution Environment is a special configuration of computer hardware and software that allows external parties to verify the exact versions of software running on the computer. TEEs allow external parties to verify that the software does exactly what the software manufacturer claims it does—nothing more or less.
The TEE’s code is the only place in the Aggregation Service which has access to raw reports—this code will be auditable by security researchers, privacy advocates, and ad techs. To confirm that the TEE is running the exact approved software and that data remains secured, a coordinator performs attestation.
Aggregatable reports are collected, batched, and send to the Aggregation Service, running on a TEE. The Aggregation Service environment is owned and operated by the same party collecting the data.
Coordinator attestation of the TEE
The coordinator is an entity responsible for key management and aggregatable report accounting.
A coordinator has several responsibilities:
Maintain a list of authorized binary images. These images are cryptographic hashes of the Aggregation Service software builds, which Google will periodically release. This will be reproducible so that any party can verify the images are identical to the Aggregation Service builds.
Operate a key management system. Encryption keys are required for the Chrome on a user’s device to encrypt aggregatable reports. Decryption keys are necessary for proving the Aggregation Service code matches the binary images.
Track the aggregatable reports to prevent reuse in aggregation for summary reports, as reuse may reveal personal identifying information (PII).
To gain insight into the contents of a specific aggregatable report, an attacker might make multiple copies of the report and include those copies in a single or multiple batches. Because of this, the Aggregation Service enforces a “no duplicates” rule:
In a batch: An aggregatable report can only appear once within a batch.
Across batches: Aggregatable reports cannot appear in more than one batch or contribute to more than one summary report.
To accomplish this, the browser assigns each aggregatable report a shared ID. The browser generates the shared ID from several data points, including: API version, reporting origin, destination site, source registration time, and scheduled report time. This data comes from the shared_info field in the report.
The Aggregation Service confirms that all aggregatable reports with the same shared ID are in the same batch and reports to the coordinator that the shared ID was processed. If multiple batches are created with the same ID, only one batch can be accepted for aggregation, and other batches are rejected.
When you perform a debug run, the “no duplicates” rule is not enforced across batches. In other words, reports from previous batches may appear in a debug run. However, the rule is still enforced within a batch. This allows you to experiment with the service and various batching strategies, without limiting future processing in a production environment.
Noise and scaling
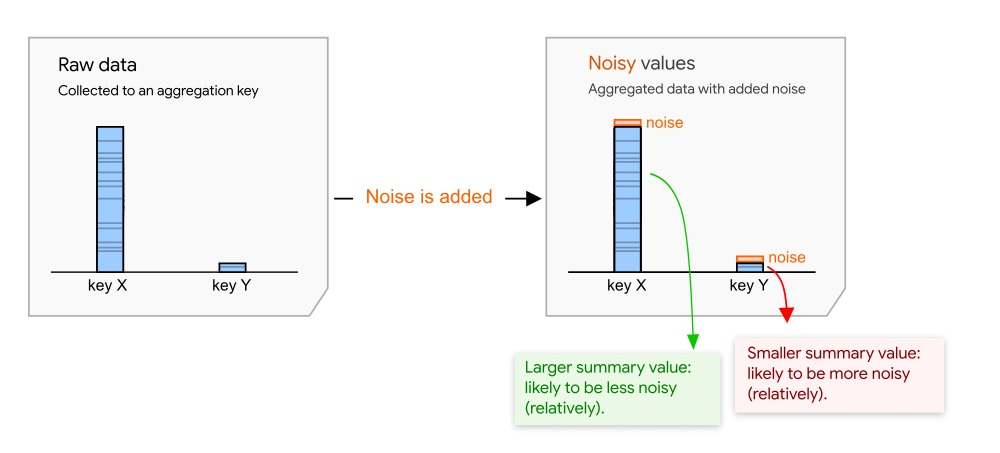
To protect user privacy, the Aggregation Service applies an additive noise mechanism to the raw data from aggregatable reports. This means that a certain amount of statistical noise is added to each aggregate value before its release in a summary report.
While you are not in direct control of the ways noise is added, you can influence the impact of noise on its measurement data.
The noise value is randomly drawn from a Laplace probability distribution, and the distribution is the same regardless of the amount of data collected in aggregatable reports. The more data you collect, the less impact the noise will have on the summary report results. You can multiply the aggregatable report data by a scaling factor to reduce the impact of noise.
A local testing tool is also available to process aggregatable reports for Attribution Reporting and the Private Aggregation API.
Engage and share feedback
The Aggregation Service is a key piece of the Privacy Sandbox measurement APIs. Like other Privacy Sandbox APIs, this is documented and discussed publicly on GitHub.
I had the pleasure of editing Carie Fisher, the author of web.dev’s latest course, Learn Accessibility. Learn Accessibility gives web developers the essentials for building accessible websites and web apps.
To promote this new content, I interviewed folks who work to build an accessible web.
Melanie Sumner told me about her journey from spy to engineer, accessible design, Ember.js, and the importance of funding these efforts.
Olutimilehin Olushuyi told me about his move from the law to web development, building accessible community, and creating accessible layouts.
Elisa Bandy told me about her work for Google’s internal teams, developing accessibility best practices for the web. Her blog post has yet to be published, but look for it in mid-December.
It’s an honor to work on Google Chrome’s developer relations team. I have the opportunity to speak with experts and offer a platform with a huge audience.
We highlighted additional resources as a part of ChromiumDev’s Accessibility Week.
The Attribution Reporting API makes it possible to measure when an ad click or view leads to a conversion on an advertiser site, such as a sale or a sign-up. The API doesn’t rely on third-party cookies or mechanisms that can be used to identify individual users across sites.
This API offers two types of reports. Event-level reports are already available for testing in Chrome, which associate a specific ad click or view with less detailed conversion data. The browser delays sending reports to ad tech companies for multiple days to prevent identity connection across sites.
A summary report (formerly known as an aggregate report) is compiled for a group of users so that it cannot be tied to any individual. Summary reports offer detailed conversion data, such as purchase value and cart contents, with flexibility for click and view data. These reports are not delayed to the same extent as event-level reports.
Today, ad conversion measurement often relies on third-party cookies. Browsers are restricting access to third-party cookies to make it more difficult to track users across sites and improve user privacy. The Attribution Reporting API allows ad techs measure conversations in a privacy-preserving way, without third-party cookies.
In contrast to Attribution Reporting API’s event-level reports, which associate singular events (such as clicks or views) to coarse data, summary reports provide aggregated data (such as the number of users who converted) attached to detailed conversion data (such as what specific product the users purchased).
Key term: Ad techs run an aggregation service that processes browser events. Noise is added to most data points reported in the event, so that no single individual’s data is discoverable in a summary report. Aggregated data is noised values relevant to measuring conversions, such as the number of users who converted.
Unlike third-party cookies, report types from the Attribution Reporting API don’t allow any entity (such as ad tech, buyers, publishers, etc) to “see” a user’s browsing behavior across multiple sites, while still making it possible to measure ad conversions.
How is user data captured and aggregated?
Note: This API is a work in progress and will evolve over time, dependent on ecosystem feedback and input. Your input helps ensure that solutions to various use cases are discussed. This API is being incubated and developed in the open. Consider participating in the discussion.
With the Attribution Reporting API, an individual user’s detailed activity across sites, and potentially the user’s identity across sites, is kept private to the user’s browser on their device. This data can be collected in an aggregatable report, and each report is encrypted to prevent various parties from accessing the underlying data.
Key term:Aggregatable reports are reports collected from individual users’ browsers. They detail cross-site user behavior and conversions, which are defined by ad tech providers.
The process to create a summary report is as follows:
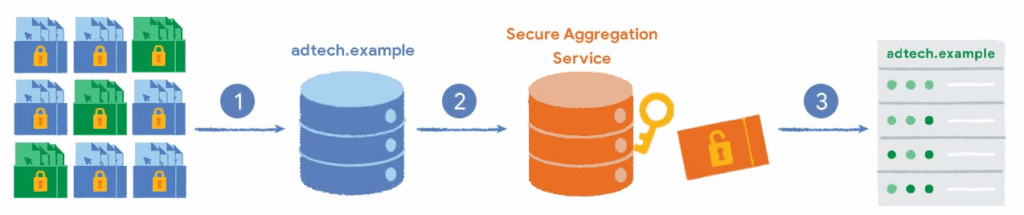
Aggregatable reports are sent to the reporting origin, operated by an ad tech provider.
These reports may include location details, number of clicks, value of the conversion (such as a purchase price), or other metrics defined by the ad tech provider. Reports are encrypted, so ad techs cannot see or access the content of any individual report.
Once the ad tech reporting origin receives the aggregatable reports, the ad tech sends the reports to an aggregation service.
In our initial implementation, the aggregation service is operated by the ad tech provider with a trusted execution environment (TEE) hosted in the cloud. The coordinator ensures that only verified entities have access to decryption keys and that no other intermediary (the ad tech, the cloud provider, or any other party) can access and decrypt sensitive data outside of the aggregation process.
The aggregation service combines the decrypted data and outputs a summary report to the ad tech provider.
The summary report includes a summary of the combined data. The ad tech provider can read and use the summary report.
Because individual reports may contain cross-site user behavior information, the aggregation service must treat this information as private. The service will ensure that no other entity can get access to the individual, unencrypted attribution reports. Further, the service itself shouldn’t perform any privacy-invasive actions.
To ensure the aggregation service is in fact secure, the service must have technical and organizational safeguards which are verifiable by consumer audit. These safeguards are meaningful to:
Individual users, who can know their individual data can only be accessed in aggregate and not by any singular entity
Ad techs, who can verify that the aggregation process uses valid data and can be monitored appropriately
Generate reports with the Aggregation Service
Key term:A trusted execution environment is a special configuration of computer hardware and software that allows external parties to verify the exact versions of software running on the computer. TEEs allow external parties to verify that the software does exactly what the software manufacturer claims it does—nothing more or less.
The initial design asks each ad tech provider to operate their own instance of the aggregation service, in a trusted execution environment (TEE) deployed on a cloud service that supports needed security features.Note: Read detailed setup instructions for the aggregation service. In the future, we intend to add support for other cloud providers that meet the aggregation service’s security requirements.
The TEE’s code is the only place in the aggregation service which has access to raw reports—this code will be auditable by security researchers, privacy advocates, and ad techs. To confirm that the TEE is running the exact approved software and that data remains secured, the coordinator performs attestation.
The coordinator has several responsibilities:
Maintain a list of authorized binary images. These images are cryptographic hashes of the aggregation service software builds, which Google will periodically release. This will be reproducible so that any party can verify the images are identical to the aggregation service builds.
Operate a key management system. Encryption keys are required for the Chrome on a user’s device to encrypt aggregatable reports. Decryption keys are necessary for proving the aggregation service code matches the binary images.
Track the aggregatable reports to prevent reuse in aggregation for summary reports, as reuse may reveal personal identifying information (PII).
To make testing of the aggregation service available in the now-complete origin trial, Google played the role of the coordinator. Longer term, we are working to identify one or more independent entities who can share this role.
What information is captured?
Summary reports offer a combination of aggregated data alongside detailed ad-side and conversion data.
For example, an ad tech provider runs an ad campaign on news.example, where a conversion represents a user clicking an ad for shoes and completing a purchase of shoes on shoes.example. The ad tech receives a summary report for this ad campaign with ID 1234567, which states there were 518 conversions on shoes.example on January 12, 2022, with a total spend of $38,174. 60% of conversions were from users buying blue sneakers with product SKU 9872 and 40% were users who bought yellow sandals with product SKU 2643. The campaign ID is detailed ad-side data, while the product SKUs are detailed conversion data. The number of conversions and total spend are aggregated data.
Conversions are defined by the advertiser or ad tech company, and may be different for different ad campaigns. One campaign could measure the number of ad clicks that were followed by a user purchasing the advertised item. Another campaign could measure how many ad views led to advertiser site visits.
How is browser data captured before aggregation?
As summary reports are made up of the data from a group of individuals, let’s start with one individual’s browser actions.
A user visits a publisher site and sees or clicks an ad, otherwise known as an attribution source event.
A few minutes or days later the user converts, otherwise known as an attribution trigger event. For example, a conversion can be defined as a product purchase.
The browser software matches the ad click or view with the conversion event. Based on this match, the browser creates an aggregatable report with specific logic created by an ad tech provider.
The browser encrypts this data and, after a small delay, sends it to an ad tech server for collection. The ad tech server must rely on an aggregation service to access the aggregated insights from these aggregatable reports.
Create a summary report
For ad tech providers to retrieve a summary report, the following steps must be taken:
The ad tech collects aggregatable reports from individual users’ browsers. Note: Ad techs can only decrypt these reports in the aggregation service. The decrypted data is not available outside of the TEE.
The ad tech provider batches the aggregatable reports and sends the batches to the aggregation service.
The aggregation service schedules a worker to aggregate the data.Note: Before the worker can aggregate, attestation is required from the coordinator. If the worker passes attestation, the decryption keys will be provided.
The aggregation worker decrypts and aggregates data from the aggregatable reports, along with noised data (a privacy mechanism for data).
The aggregation service returns the summary report to the ad tech provider.
The ad tech can use the summary report to inform bidding and to offer reporting to its own customers. A JSON-encoded scheme is the format for summary reports.
High-level overview of connected services for Attribution Reporting, aimed at technical decision makers.
The Attribution Reporting API allows ad techs and advertisers to measure when an ad click or view leads to a conversion, such as a purchase. This API relies on a combination of client-side and server-side integrations, depending on your business needs.
You’re an ad tech or advertiser’s technical decision-maker. You may work in operations, DevOps, data science, IT, marketing, or another role where you make technical implementation decisions. You’re wondering how the APIs work for privacy-preserving measurement.
You’re a technical practitioner (such as a developer, system operator, system architect, or data scientist) who will be setting up experiments with this API and Aggregation Service environment.
Continue to read a high-level, end-to-end explanation of how the services work for the Attribution Reporting API. If you’re a technical practitioner, you can experiment with this API locally.
The Privacy Sandbox proposals are the first of many steps required to create web platform features.
These web platform features may become web standards (also known as specifications or specs), which are technical documents that detail exactly how web technology should work and define how engineers should implement the technologies in web browsers. For example, the Accessible Rich Internet Applications (WAI-ARIA) standard (commonly known as “ARIA”) defines technical ways to make the web more accessible to those with disabilities. These specs are developed for and by the World Wide Web Consortium (W3C), an international community with full-time staff, member organizations, and feedback from the general public.
After discussion, testing, and scaled adoption, some Privacy Sandbox proposals and APIs will become specs. It’s critical we receive feedback from developers and industry leaders (with and without web technology knowledge) to ensure we create durable web features with broad utility and robust privacy protections for users.
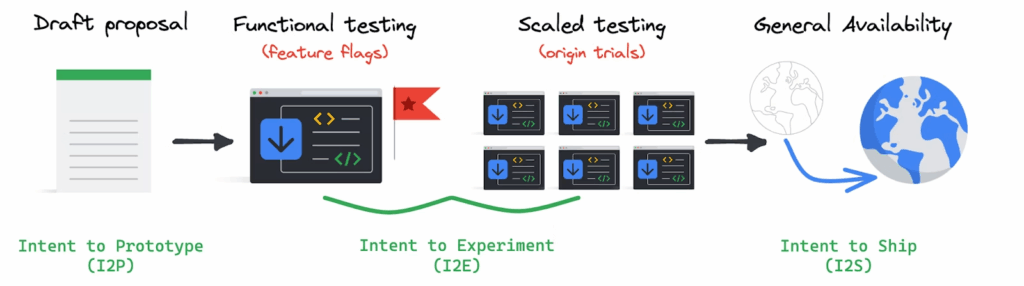
Figure 1: Features progress through a timeline of development and testing through to general availability. The intents are hard boundaries, which are required before certain actions can take place. For example, testing cannot begin until an Intent to Experiment has been posted and received approvals. Learn more about these requirements.
Chromium (the open source project behind many modern browsers) has written about the feature development process for all technologies which aim to become a web standard. Because of the critical nature of privacy and security on the web, we expect and encourage large amounts of discussion and feedback before testing begins.
This year I was invited to speak at Build Stuff in Lithuania and Ukraine. I hoped to convince developers that writing docs would make them better engineers, better colleagues, and better future-proofers.
Some of the talks I saw which deserve your attention:
In this conversation, we talked about what it’s like to work on Google’s tech writing team and my previous experience at Joyent. I spoke about the importance of multimedia documentation, creating proposals to tear down bad docs, and what it has been like to join the conference circuit.
Just a note, this conversation was one of my own and not on behalf of Google or Alphabet. My thoughts are not those of my employer’s.